
Data Architecture for huge daily data volume
Recently we created a cloud native Data Exchange Platform to deal with large volume of data.

Recently we created a cloud native Data Exchange Platform to deal with large volume of data.
We were pulling in data from various sources which spanned from APIs to Databases to flat files. The daily data volume was about 10 TB and we wanted to transform and make this data available not only to our AI and BI teams but also to application developers.
So after some cost analysis we decided to go with AWS.
Key Attributes
All data in one place
Decoupling Storage vs Compute
Schema on read
Rapid ingest and transformation
AWS Detailed View
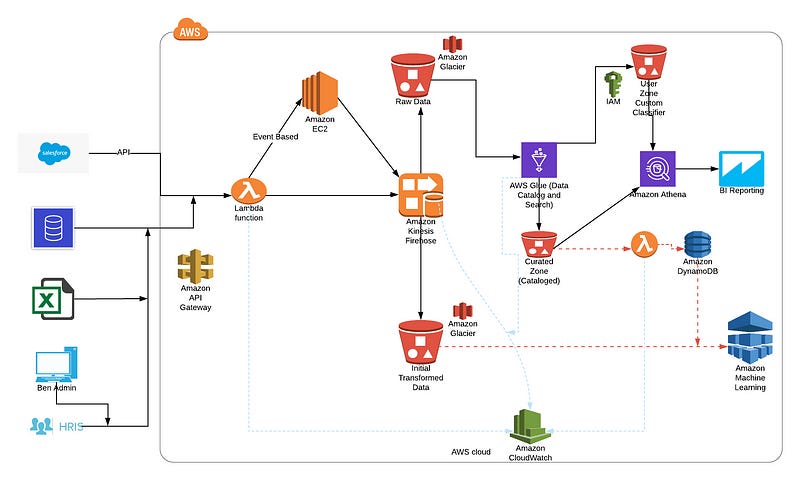
The diagram above is divided into three zones:
RAW Zone
This has data specific to the sources. This contains tables which capture raw data in the source format.
For example data from HRIS or Ben Admin will not be transformed.
Curated Zone
This contains data organized by business process. This data is cleaned and transformed.
User Zone
This contains user specific data